Blog
How to Enhance Search Experience with RedisSearch
Searching is a common requirement for any application, providing users with an efficient and intuitive search experience is a critical aspect of user satisfaction. The ability to quickly find relevant information has become a cornerstone for successful applications. In this article, let’s explore how we can leverage RedisSearch, a Full-text Search engine, available as a module for Redis. We'll use Python as our example language, providing a hands-on approach to leveraging this powerful tool.
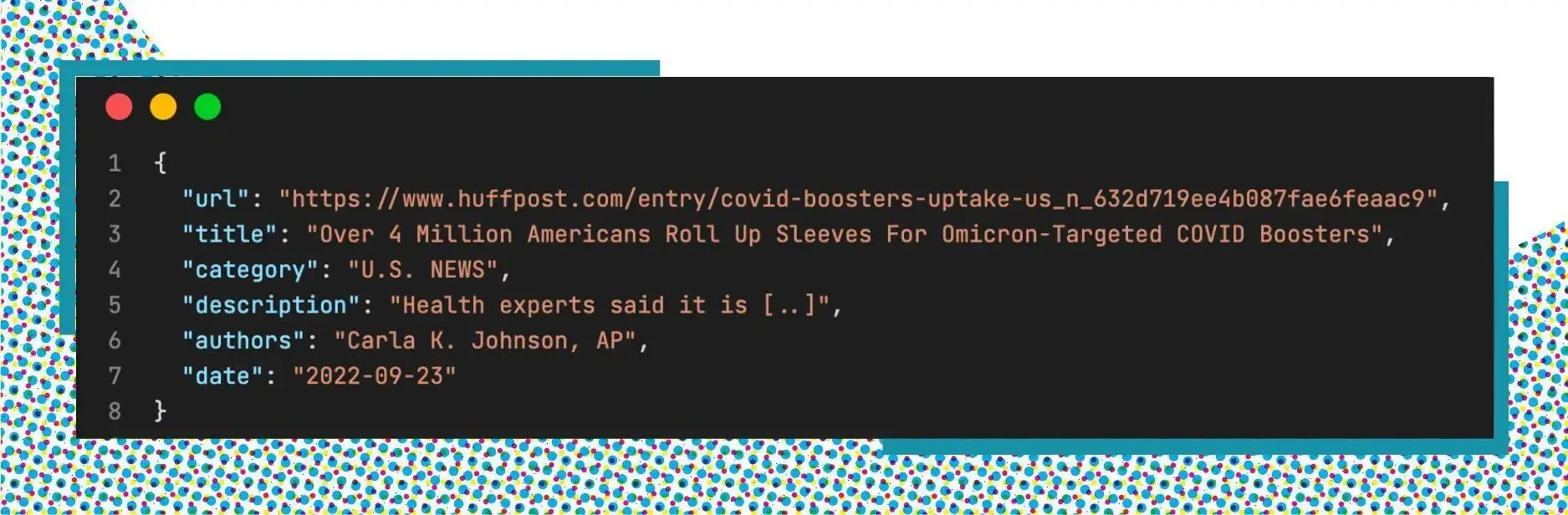
Throughout this article, we will build a simple search API that lets users search news from News Category Dataset (210k news articles). To simplify, we only use 10% of this dataset (20k articles).
- Here is the basic structure of an article:
Search and UX
There are many factors for building a good search interface. Among all of them, I want to emphasize these 2 key points:
- Three-click rule: The Three-click rule suggests that a user should be able to find any information with no more than three mouse clicks. It is sort of a myth but also something we should aim for. One example of this rule could be the famous Google's minimalist and user-friendly search bar.
- Speed matter: A critical aspect of user satisfaction is the speed of search response. But how fast is “fast enough” for the response? We can reference this graph below from redisconf 2018. Ideally, it should be from 50ms to 500ms.
 Source: redisconf 2018
Source: redisconf 2018
To make searches fast and easy, we can implement autocomplete and full-text search, which will be introduced next.
Autocomplete
The autocomplete pattern has revolutionized search interfaces. By providing users with suggestions as they’re typing, autocomplete makes searching easy and effortless.
There are 2 simple steps to implement this powerful feature: adding suggestions and querying results.
Implementation
Adding auto-complete suggestions
For each article in the dataset, we will add a suggestion to the auto-complete suggestion dictionary of RedisSearch.
To add a suggestion string to an auto-complete suggestion dictionary, we use the command FT.SUGADD.
💡 This tutorial uses the official Python client for Redis.
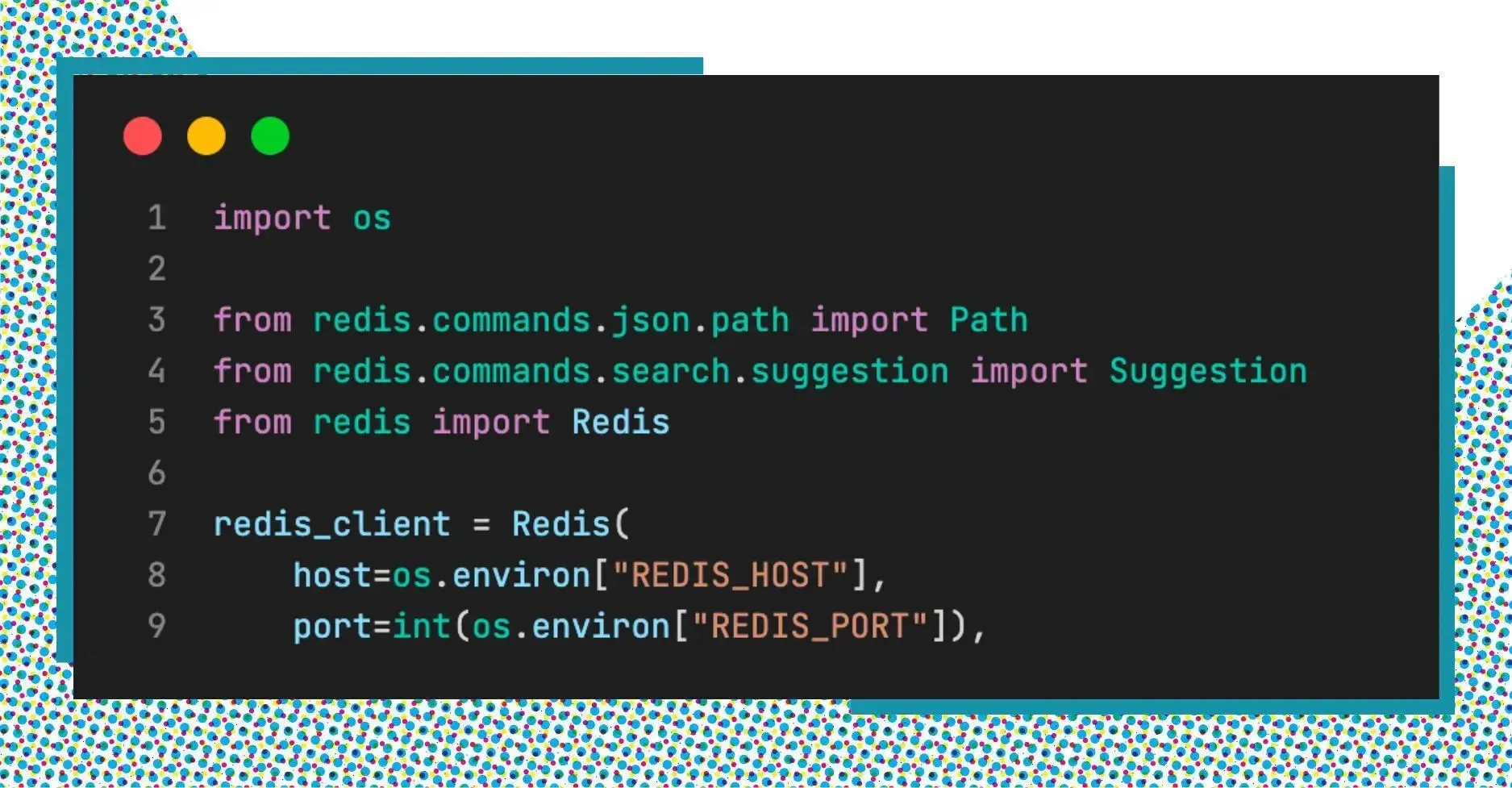
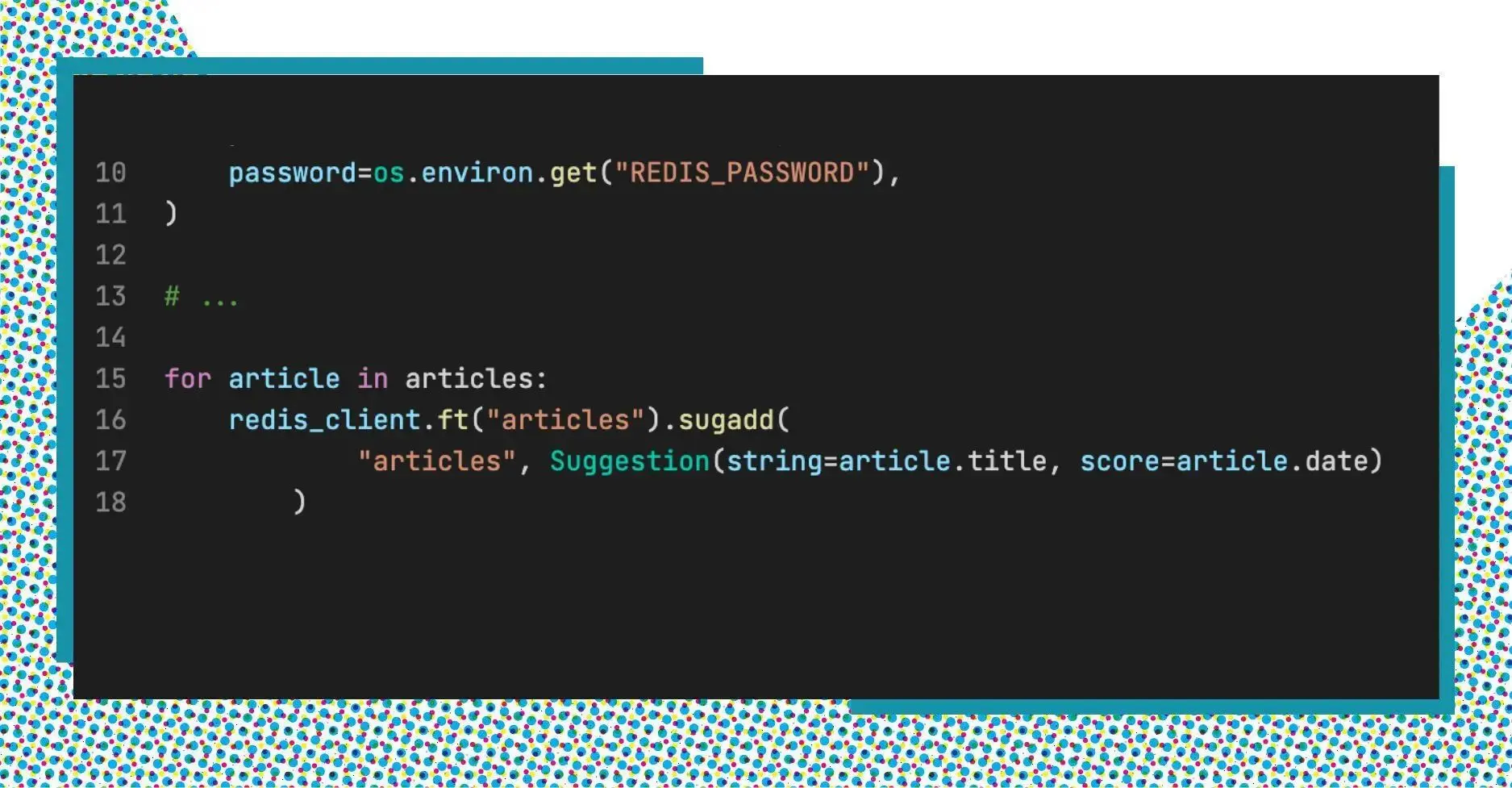
There are 2 main parameters in the command FT.SUGADD:
- key: A key for the auto-complete suggestion dictionary.
- suggestion: A suggestion to be added.
Querying auto-complete suggestions
With the autocomplete suggestion dictionary in place, we can now retrieve a list of suggestions for a given prefix using the FT.SUGGET command.
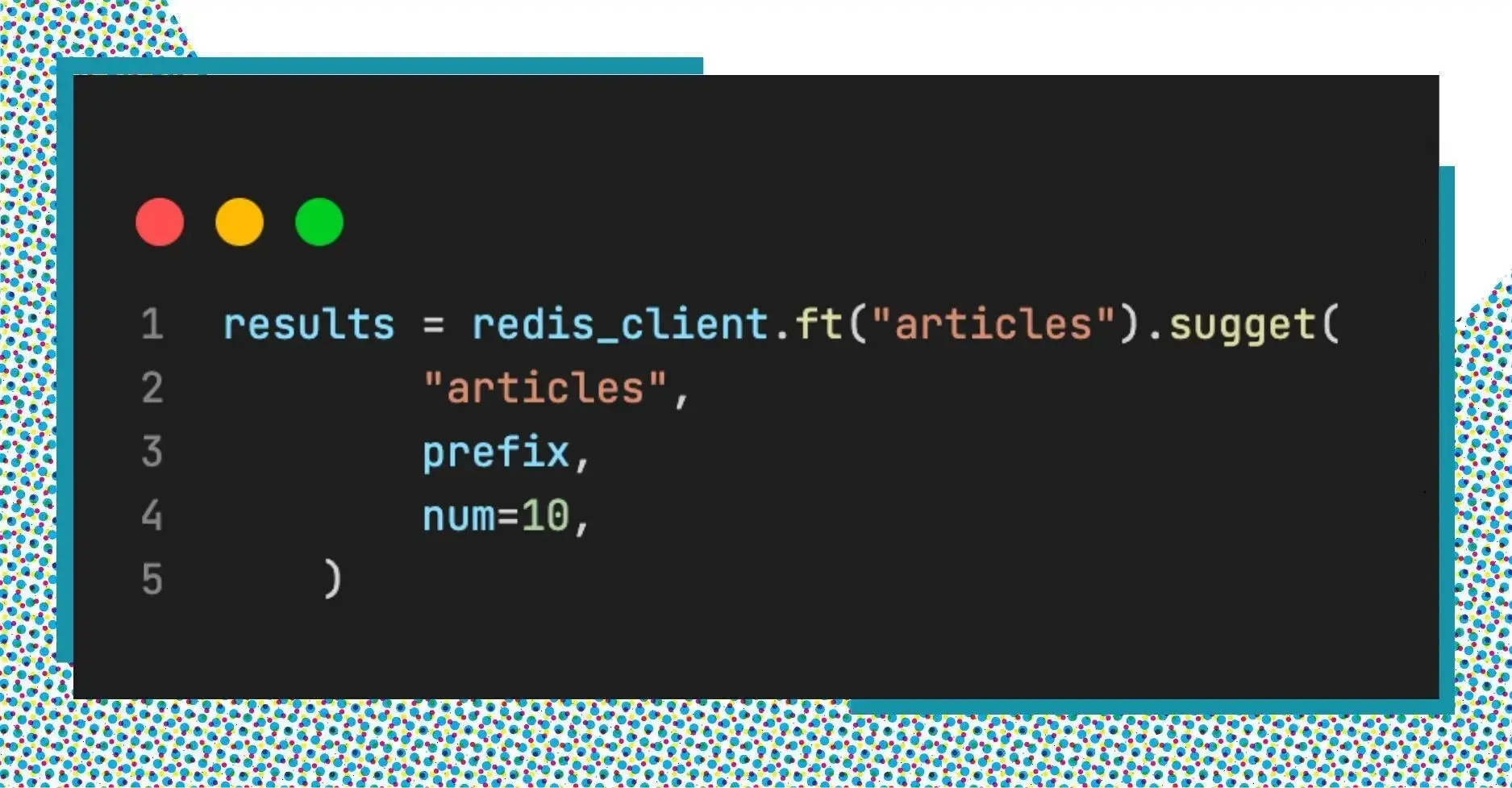
There are 3 main parameters in the command FT.SUGADD:
- key: A key for the auto-complete suggestion dictionary.
- prefix: the prefix we are searching.
- num: the maximum number of returned results.
That's the basics! Pretty straightforward, isn't it? For more complex cases, read on to solve the challenge of handling keywords within the text.
Full-text search
The autocomplete feature above only handles the prefixes. If users type keywords that are in the middle or even at the end of the text, autocomplete can not suggest the expected results.
Let's say we have 5 article titles:
- The London housing market saw record growth in Q3.
- London prepares to host a global tech conference.
- London bridge renovation project reaches milestone.
- A new study highlights London's cultural diversity.
- Tech startups thrive in London's innovation hub
If we query “London” using autocomplete, it only returns the first 3 articles. In reality, we would expect users to be able to see all 5 results above.
Or in a worse scenario, if users misspell “London” with “Londin” in the query, they will not see any results as “Londin” does not appear in any of those article titles.
Full-text search is the solution to those problems. It is a technique that allows searching for documents or data based on the presence of keywords or phrases within the document's entire text. Unlike traditional search methods, full-text search considers the context, synonyms, and word proximity to provide more relevant search results. This ensures a better user experience and increased user satisfaction.
Full-text search engines use algorithms to index the content of documents or data sources to make them searchable.
We can implement and test a Full-text search through 3 steps:
- Initialize the index.
- Import data.
- Query data.
Initialize the index
First, we need to define the schema for the index. For example, let’s define a schema for news articles like below:
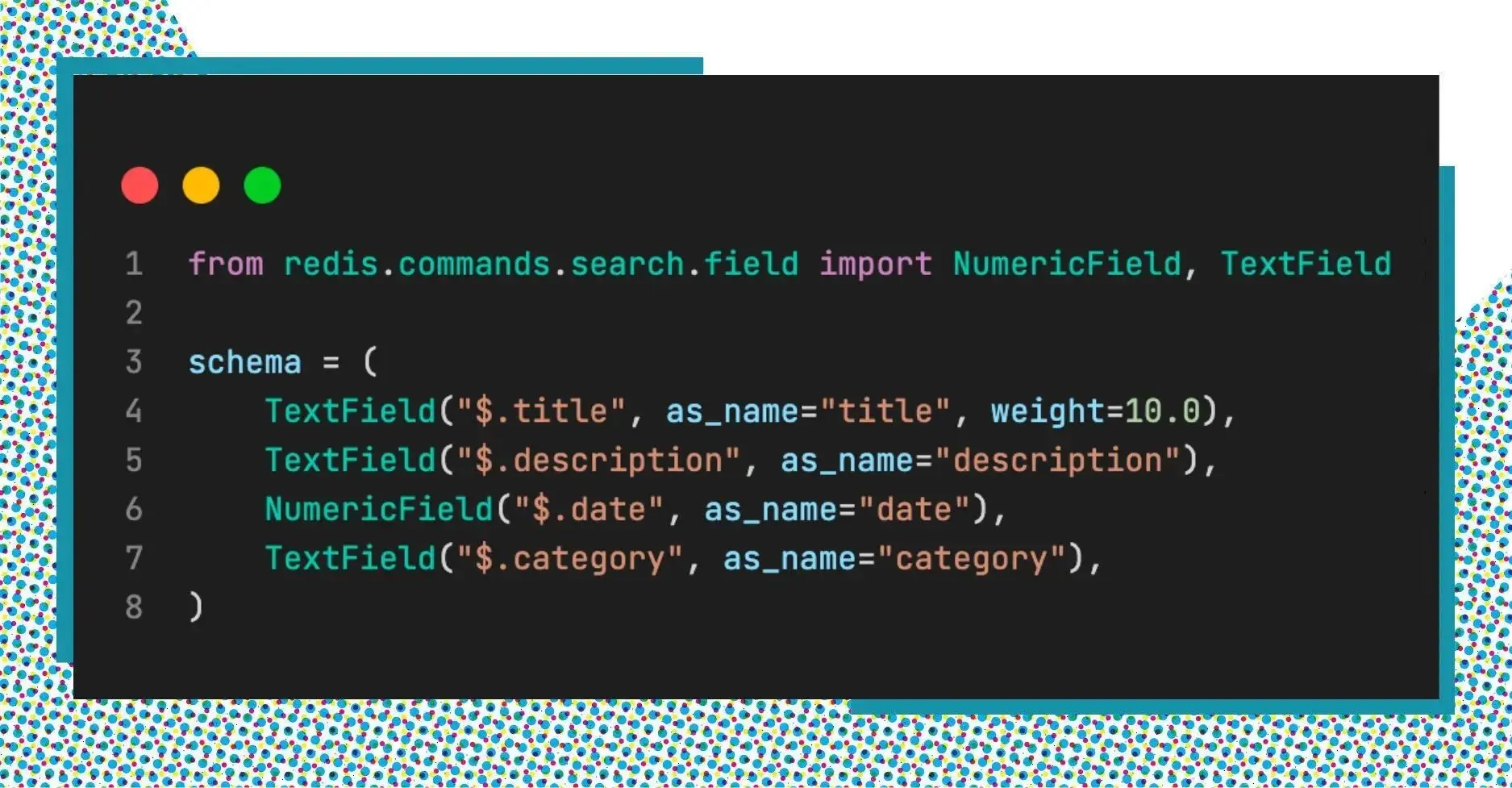
RedisSearch uses the weight parameter to rank the result set on querying data. By default, every field has a weight of 1, meaning RedisSearch will not consider whether the keyword is in the title or description.
However, we want to prioritize articles with the keyword in the title over those with the keyword in the description. As a result, we increase the weight of the title to suit our needs.
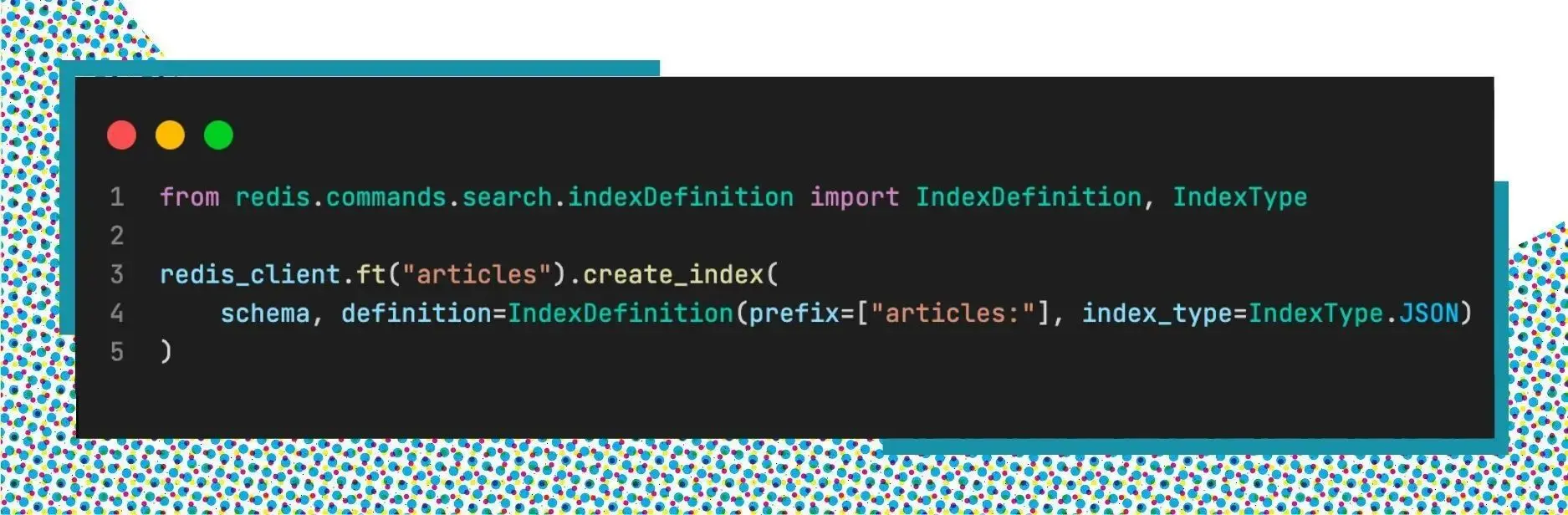
After having the schema, we will create the index using the command FT.CREATE.
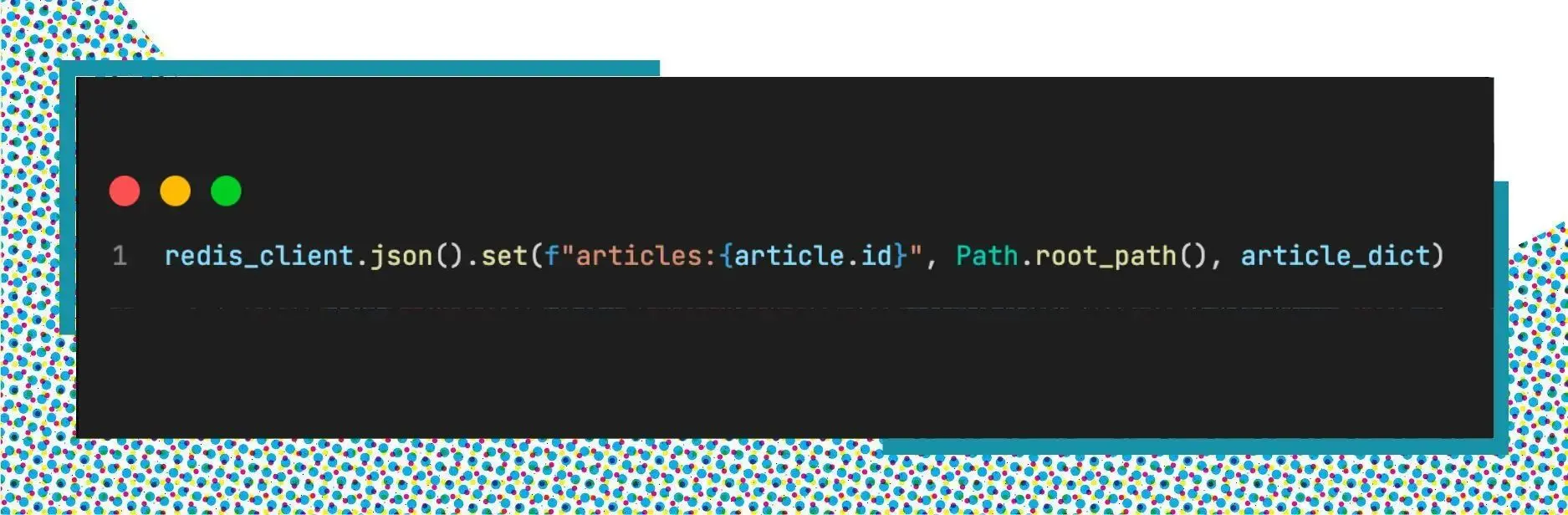
Import data
Next, we need to import all the articles to Redis using the command JSON.SET.
This step gradually happens in real-life applications when we slowly append more data to Redis and the data should exist before searching. In this article, we import all data one time to be able to do the full-text search.
For more details, you can check this notebook in the demo repo.
Query data
Then, the search function can be finally implemented.
Build the query

Pretty simple. However, in some cases, users might want broader results. Luckily, RedisSearch also supports Fuzzy matching. We can simply add ‘%’ around the term to apply Fuzzy matching.
Fuzzy matching or approximate string matching is the technique of finding strings that match a pattern approximately (rather than exactly).
Execute the query
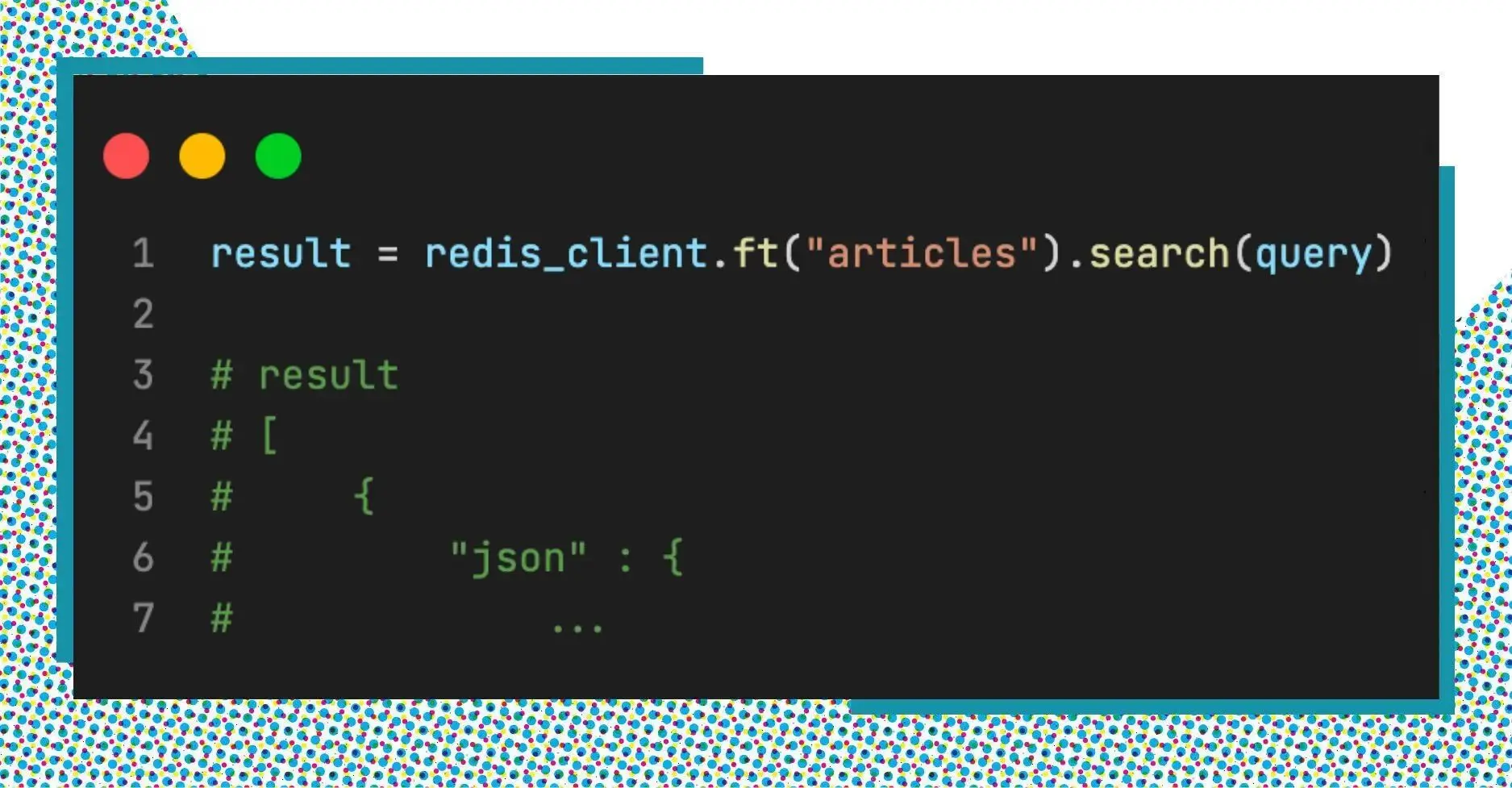
After having the query, we can use the command FT.SEARCH to get the results.
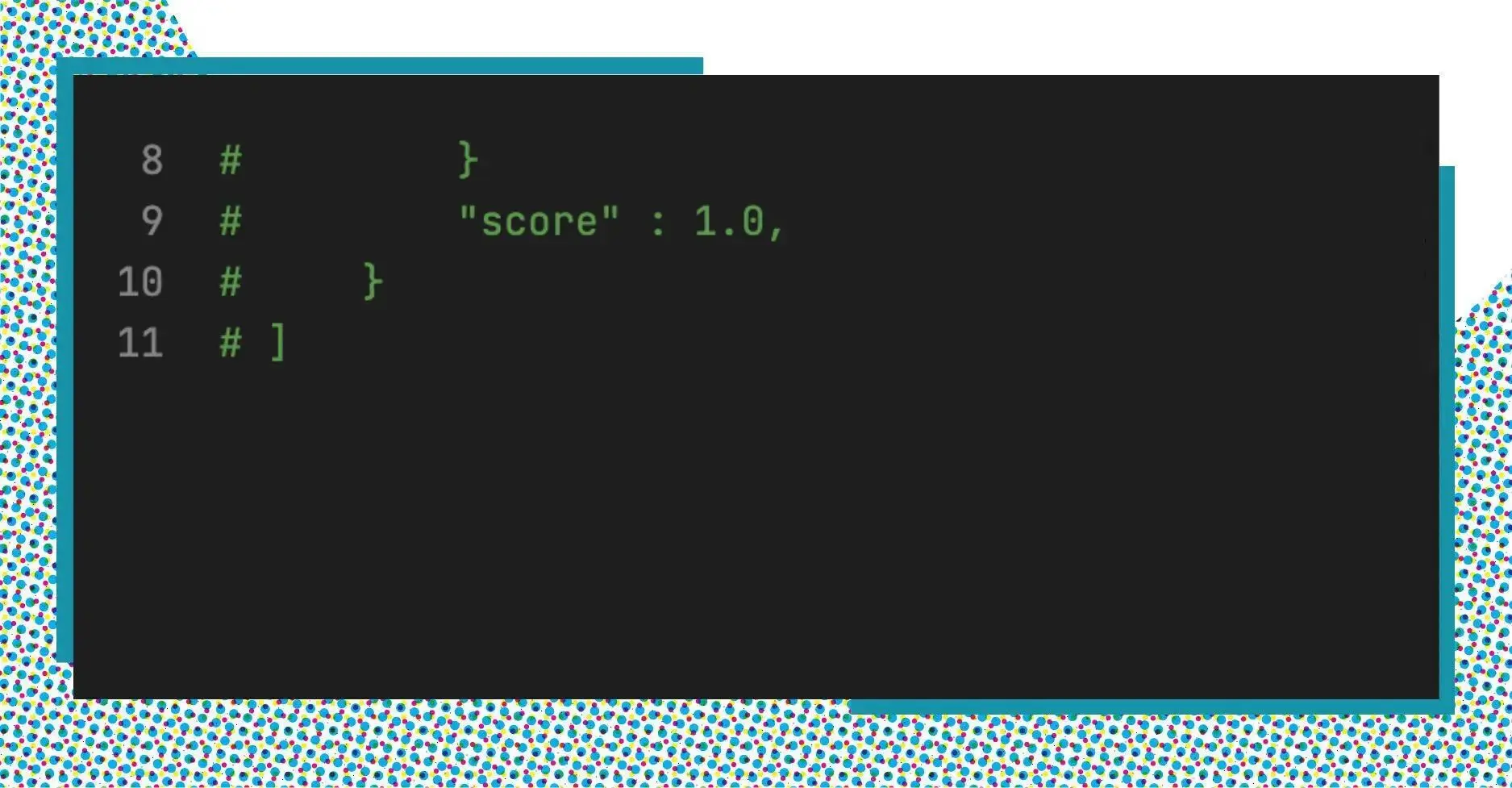
This command returns a list of documents. Each document has 2 main fields:
- json: A json data that we have set.
- score: the value indicates how relative this document is to the query.
Others
Filtering
Besides full-text searching, FT.SEARCH also supports filtering by particular fields.
General syntax: @field_name: value1 | value 2. For example, if we want to return only articles on BUSINESS and ENTERTAINMENT categories, we will add @category: BUSINESS | ENTERTAINMENT to our query.
There are multiple types of advanced filters:
- Numeric filters and ranges.
- Geo filter.
You can find more details here.
Sorting
The result set can be returned in order of any fields using the SORTBY parameter. The order can be ASC or DESC.

Pagination
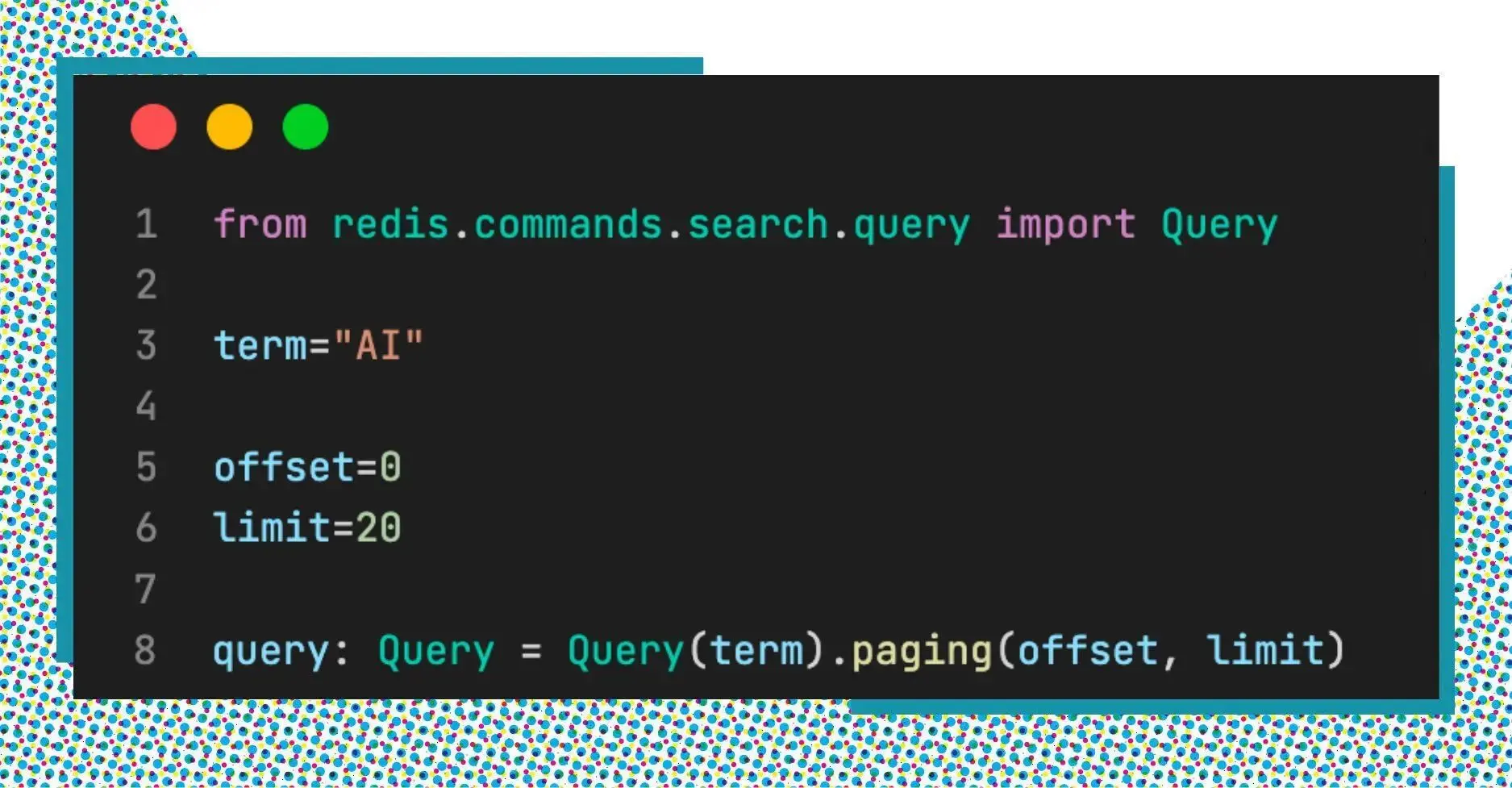
How about when we have a large amount of data, and you want to return a part of them? Does it sound like pagination?
Simply add the LIMIT parameter to our query. It takes 2 numbers: offset and limit. Note that the offset is zero-indexed. The default is 0 10, which returns 10 items starting from the first result.
Conclusion
In this tutorial, CodeLink have explored RedisSearch, a powerful Full-text Search engine integrated with Redis, using Python. We covered autocomplete suggestions, efficient full-text searches, data import, and advanced querying techniques.
By implementing these features, you can create a seamless and intuitive search experience for your users. RedisSearch helps your implementation fast and easy, providing more value to your users.
For a hands-on experience, you can access the demo code on our GitHub repository.
Happy coding!



