A Practical Guide to AI Agent Evaluation
Learn how to assess AI agents with structured evaluation frameworks, from model and product testing to scenario-based analysis, performance metrics, and continuous monitoring.

A Practical Guide to AI Agent Evaluation
Deploying an AI agent without a robust evaluation strategy isn't just a technical oversight; it’s a business risk. Inconsistent behavior can damage brand reputation, while inefficient models can silently drain profitability.
This guide explains how to ensure your AI investment delivers real value, not just code.
Why Agent Evaluation is Harder Than You Think
The core difficulty in evaluating an agent is that we have to evaluate not only the final output but also the trajectory and steps that bring it to the final answer. Agents interpret context, choose actions, and interact with systems in dynamic ways. Their outputs emerge from reasoning processes rather than predefined rules, which complicates direct comparisons against a single “correct” answer.
Unlike traditional software systems that behave deterministically, AI agents introduce variability at every layer. Minor changes in prompts, model versions, or even execution timing can produce different outcomes for the same input. This variability makes agent behavior harder to anticipate and harder to validate through fixed expected outputs.
How to Know if Your Agent is Under-Evaluated
Without systematic evaluation, failures often surface only after they reach end users. The following signs typically indicate that an agent is not being monitored or assessed effectively:
-
High Variance in Answers: The agent gives excellent answers on Monday, but hallucinates on Tuesday with the exact same input.
-
Escalating Compute Costs: Operational costs increase while task success rates remain flat. This suggests the agent is looping inefficiently or using too many tokens to solve simple problems.
-
Negative Customer Interactions: Users report interactions that feel "off," repetitive, or robotic in a way that damages brand trust.
Evaluation vs. Testing: Understanding the Difference
Before diving into methods, let's clear up a common confusion: evaluation and testing aren't the same thing.
Testing is binary. It asserts correctness with two values: pass or fail. An easy example would be employee attendance check: if an employee shows up to work, they pass; if not, they fail. Tests are gatekeepers in the sense that if your app doesn't pass, it simply doesn't ship.
Evaluation, on the other hand, measures performance against metrics that can be fuzzy, subjective, or probabilistic. It’s most useful when comparing systems rather than making absolute judgments. A useful analogy is an employee’s annual performance review. Instead of pass or fail like above, the assessment considers factors like communication, initiative, teamwork, problem-solving, etc.

That said, these concepts overlap. You can turn evaluation metrics into regression tests, like asserting that any new version must outperform the baseline by at least 5% on key metrics. And in practice, we’ll often run both together to save on compute costs.
How to Evaluate Agents with Confidence
Now that it's clear why evaluation is critical, let's walk through the practical steps to implement it:
Step 1: Choose an Evaluation Method
AI evaluation isn't one-size-fits-all. Before selecting metrics or tools, you need to understand what type of system you're evaluating. The approach differs significantly across three categories:
-
LLM Model: is a raw foundation model (like GPT-4, Claude, or Gemini-2.5-flash) that has been pre-trained on massive datasets. These models have general-purpose capabilities but haven't been customized for specific tasks.
-
Agent: is an autonomous system built on top of an LLM Model that can perceive its environment, make decisions, plan multi-step actions, use tools, and adapt its behavior to achieve goals.
-
Product: is a complete LLM-powered system that combines the base model with custom components, such as prompt engineering, retrieval-augmented generation (RAG), orchestration logic, domain knowledge, and external integrations.
LLM Model vs. Product vs. Agent Evaluation
| Evaluation Category | LLM Model | Agent | Product |
|---|---|---|---|
| Purpose | Measure a base model’s general capabilities across broad tasks. | Measure whether an agent can reliably achieve goals in dynamic environments. | Measure how the full LLM-powered system performs for a specific use case. |
| Primary Focus | Reasoning, coding, translation, mathematics, comprehension. | Decision-making, planning, action execution, adaptability, robustness. | Domain-specific accuracy, response quality, system reliability, and production readiness |
| Data Type | Standardized benchmarks (MMLU, HumanEval, HellaSwag). | Scenario scripts, simulations, multi-step tasks, and interactive environments. | Domain-specific datasets and real-world scenarios. |
| Evaluation Method | Diverse questions to test generalization. | Multi-step evaluation across actions, reasoning traces, and final outcomes. | Consistent criteria applied to varied real-world inputs. |
| Metrics | Accuracy, BLEU, ROUGE,... | Goal fulfillment, plan quality, consistency, decision quality, resource efficiency. | Latency, cost, resilience, end-to-end quality. |
| What It Reveals | How strong the model is in a specific task. | How effectively an agent behaves, adapts, and makes decisions. | How well does the overall system solve the intended problem? Is it ready for deployment? |
| Who Uses It | Model developers and researchers. | Agent developers, R&D teams, and product teams working with autonomous systems. | Product teams, QA, and applied ML engineers. |
| When to Use It | Selecting or comparing base models. | Ensuring agents perform reliably before and after deployment. | Validating product readiness and monitoring production performance. |
Offline vs. Online Evaluation
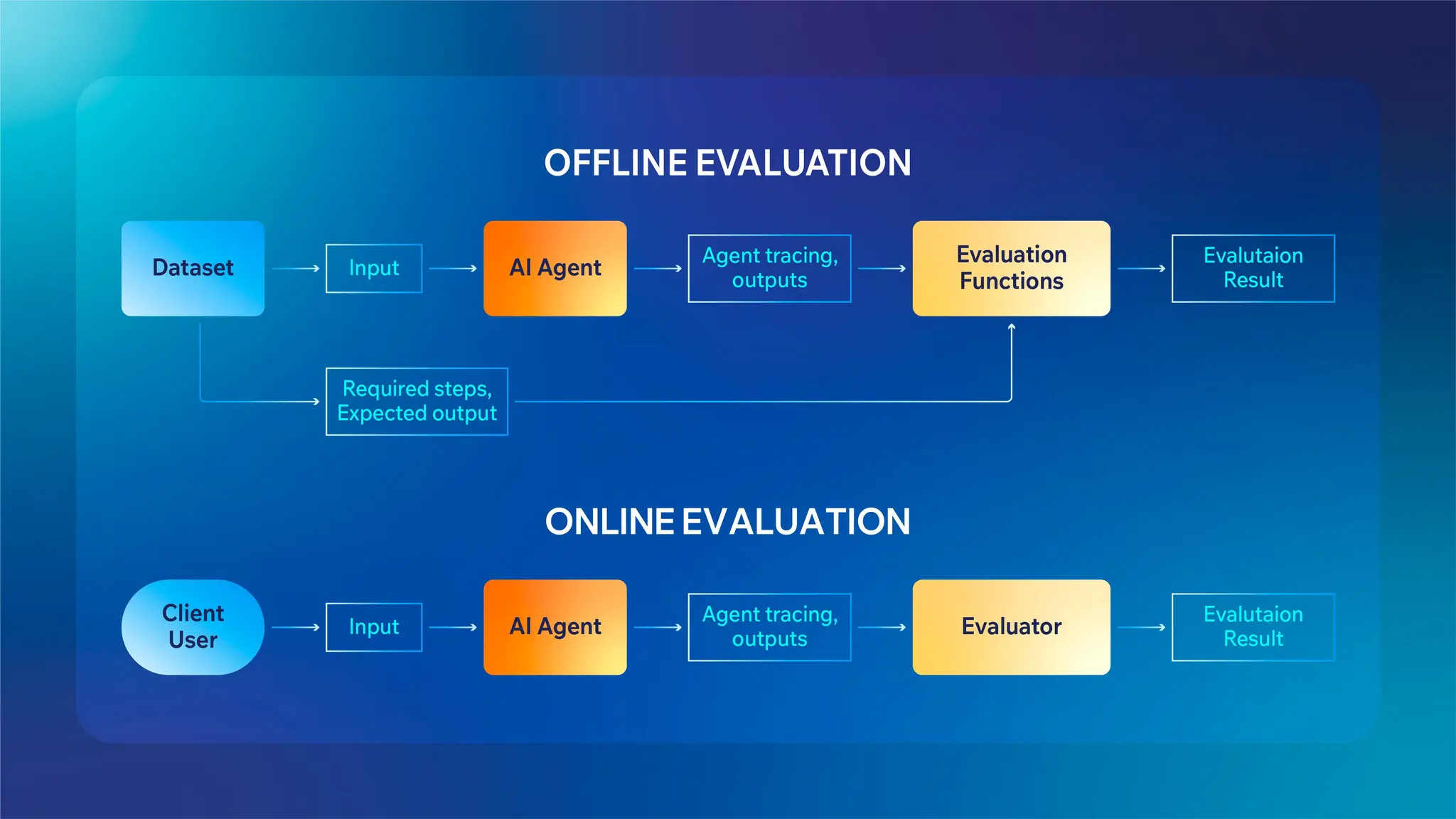
Offline evaluation serves as the "Simulator" before deployment. It’s a controlled, pre-deployment assessment where an agent is tested against curated datasets and simulated scenarios to analyze its performance without affecting real users.
This method provides a safe, risk-free environment to experiment, iterate, and analyze agent behavior. To prepare for an offline evaluation, you usually need to prepare:
-
A dataset: contains test inputs, agent action tracing, and optional expected outputs.
-
Evaluation functions: functions that score actions and outputs based on defined criteria.
Online evaluation is the “Moderator” in production. Online evaluation is a real-time assessment of an agent’s behavior in production, using live user interactions to monitor performance, detect regressions, and surface issues that only appear under real-world conditions.
There's no pre-compiled dataset here, only actual user inputs and outputs as they happen. This immediate oversight is crucial not just for monitoring and flagging unexpected behavior, but also for enforcing safety guardrails against toxicity or PII leakage on the fly. Furthermore, it enables rapid A/B testing to compare model variants against live traffic and detects concept drift, ensuring the model’s quality doesn’t degrade over time. Online evaluation is a continuous improvement engine; valuable insights can be fed back into offline evaluation pipelines.
Both modes complement each other. Offline evaluation accelerates iteration, while online evaluation protects real users.
Step 2: Choose the Right Metrics
You can't improve what you don't measure, and focus on measuring what matters. Here are the core metrics for AI agent evaluation you should consider next:
| Metric Category | Example Metrics | The Business Question | Strategic Impact |
|---|---|---|---|
| Operational Efficiency | Response Latency, Token Usage per Task, Compute Cost per Run | "Is this agent burning cash or saving time?" | Cost Control & Retention: High latency kills user engagement, while unoptimized token usage inflates monthly OpEx, destroying margins. |
| Decision Intelligence | Goal Fulfillment Rate, Hallucination Rate, Logical Path Validity | "Can I trust this agent to act without a human babysitter?" | Autonomy & Scale: If the agent makes poor decisions, humans must intervene. High decision quality is the only way to achieve true automation and labor savings. |
| Reliability/Consistency | Variance in Outputs, Reproducibility Score, Stability across versions | "Will the agent embarrass us on a bad day?" | Risk Mitigation: An agent that gives different answers to the same question creates liability. Consistency protects your brand reputation and user trust. |
| Outcome Effectiveness | Task Success Rate, User Acceptance / CSAT, "Time to Resolution" | "Did the user actually get what they came for?" | Revenue & value: Speed and cost don't matter if the problem isn't solved. This metric is the ultimate measure of product-market fit and ROI. |
Step 3: Implement Evaluation Methods
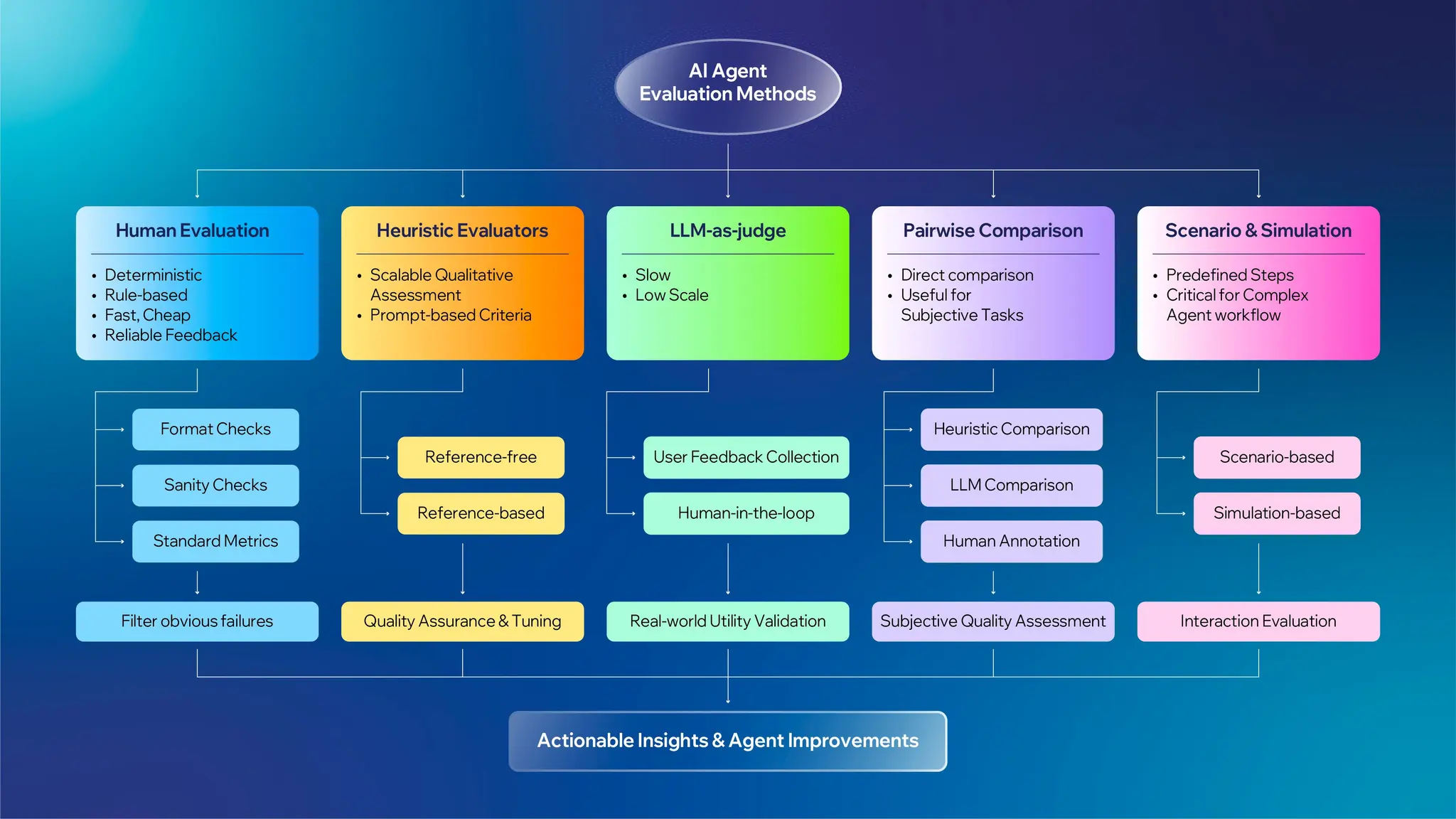
Once you know what type of evaluation you need and what metrics to look for, the last question is: how do you score the outputs?
Here are the main approaches to implement AI agent evaluation:
Heuristic Evaluators
If you have a predefined dataset, this should be your first consideration. Heuristic evaluators are deterministic, rule-based functions that provide immediate, cost-effective feedback. They are ideal for validating structural integrity and exact matches, such as:
-
Format Checks: Does the output parse correctly as JSON or XML?
-
Sanity Checks: Is the response non-empty and within token limits?
-
Standard Metrics: Calculating n-gram overlaps like ROUGE or exact classification matches.
Because they are fast, cheap, and reliable, heuristics allow you to filter out obvious failures before engaging other evaluation methods.
LLM-as-Judge
LLM-as-Judge is using an LLM to evaluate other LLM outputs by encoding grading criteria into a prompt. In this setup, the LLM acts as an automated judge, assessing qualities like factual accuracy, tone, relevance, or adherence to instructions.
This method provides 24/7 quality assurance at a fraction of traditional human review costs. It scales qualitative assessments that would otherwise require armies of human annotators, evaluating thousands of outputs per hour instead of dozens.
Two common patterns:
Reference-free: evaluates outputs without a correct answer
-
Example: "Does this response contain offensive content?" or "Is the tone professional?"
-
Best for: Subjective criteria (safety, tone, helpfulness) where there's no single right answer
Reference-based: compares output to a provided correct answer
-
Example: "Is this summary factually consistent with the source document?" or "Does this answer match the expected solution?"
-
Best for: Objective criteria (correctness, completeness) where you have known-good examples.
Pro tip: Review the scores carefully and tune your grader prompt. Few-shot examples with input-output-grade triples often work better than zero-shot.
Human Evaluation
Having human reviewers directly assess agent outputs, execution traces, and decision quality. This involves real people examining whether responses are accurate, helpful, safe, and aligned with user intent.
This method is slow and doesn't scale, but it's the best way to validate whether your agent is useful in the real world. So, collect feedback directly from users and use this method early on to set baselines and calibrate automated evaluators.
Pairwise Comparison
For many real-world tasks, it’s easier to decide “which of these two answers is better?” than to assign a precise score from 1 to 10. Pairwise comparison turns agent evaluation into an A/B test: you compare two versions of an agent (or two model configurations) on the same set of prompts and simply pick the better output.
In business terms, this is most useful when you are tuning experience and tone rather than checking hard facts. For example: which version writes clearer support replies, closes more leads with outbound emails, or produces briefs your team actually uses. It works well for:
-
Customer support replies (which answer is more helpful and empathetic)
-
Sales outreach (which email gets more replies or meetings booked)
-
Internal summaries and reports (which version is clearer and more actionable)
Under the hood, the “judge” can be a human reviewer, a set of business heuristics, or another LLM. Either way, the output is simple: version A wins or version B wins. Over a large sample, this gives you a clear signal about which agent version to roll out, without requiring your team to design complex scoring rubrics.
Scenario-based and Simulation Testing
Scenario-based testing means defining a set of “must not fail” situations and checking how the agent behaves in each of the decision steps before or after launch.
Think of it as a checklist of dangerous or high-value moments: an angry VIP customer, a refund request above a certain amount, a user asking about regulated content, or a system outage in one of your warehouses. You can script these scenarios and see whether the agent follows policy, escalates correctly, and protects your brand.
Simulation testing goes a step further. Instead of isolated cases, you create a safe environment that mimics real operations: thousands of synthetic customer chats, simulated order flows, or virtual agents calling your internal APIs.
This lets you answer questions like: “What happens to average handling time during peak season?” “Does the agent create bad orders when inventory data is delayed?”, or “If the pricing logic changes, does the agent still quote correctly?”
For business stakeholders, the value is straightforward:
-
Reduce the chance of expensive failures (wrong refunds, compliance breaches, bad trades or orders)
-
Understand how the agent behaves under stress (traffic spikes, partial outages, noisy data)
-
Build confidence with risk, legal, and operations teams before scaling up automation
Conclusion
Evaluating AI agents is a continuous process of building better agents, not just measuring them. Start with human evaluation to understand what good looks like. Build heuristic and LLM-based evaluators to scale your assessments. Use offline evaluation to iterate quickly, and online evaluation to catch issues in production. Benchmark regularly, run regression tests, and track metrics that actually matter.
Building an agent is easy; trusting it is hard. Don't let your evaluation strategy be an afterthought. Contact CodeLink today to audit your current AI roadmap and ensure your agents are ready for the real world.

Luu Ngo
Senior AI Engineer
Luu is a skilled AI Engineer specializing in Computer Vision, Natural Language Processing (NLP), and Large Language Models (LLM). He has successfully contributed to a variety of projects that showcase his technical expertise and creativity.




